


没有人不在期待大模型能够成为下一个电动车,作为代表中国的新兴产业,在世界范围内掀起狂澜。
然而主流的MoE架构大模型,却苦于其结构上的“先天不足”:巨大的硬件成本与多重拖累效率的环节,使得中国企业在这场芯片堆砌与效率挖掘的苦径上难以提速。
作为智能基础设施提供商,华为在这场战役中另辟蹊径,利用其在数学算法和工程领域的深厚积累,为DeepSeek显著提升了效率及用户体验。
山就在那里,但中国企业找到了不一样的登顶之路。
大火的MoE专家网络,也有冷热不均的问题
在人工智能技术日新月异的当下,大语言模型的发展持续突破边界。混合专家模型(MoE)作为提升大语言模型性能的关键技术,近年来备受瞩目。
它通过将输入 token 分配给不同的专家网络,实现了模型的高效扩展,让模型在处理复杂任务时展现出更强的能力。然而,如同硬币的两面,MoE 模型在发展过程中也面临着严峻挑战,其中负载均衡问题尤为突出。
在混合专家(MoE)模型的推理过程中,专家调用频率的不均衡性,即“冷热专家”现象,导致负载分布显著不均,严重影响系统推理性能。这一问题源于部分专家(热专家)被高频调用,而其他专家(冷专家)使用率极低,调用频率差距可达一个数量级以上。具体而言,该问题表现为以下几个方面:
负载不均:部分专家(热专家)被频繁调用,而其他专家(冷专家)使用率较低,频率差距达到一个数量级以上。
推理延迟增加:负载不均衡导致慢速计算节点成为推理瓶颈,延长整体推理时间。
吞吐量受限:资源利用率不足,限制系统性能。
显著提升MoE模型推理性能的极致均衡技术
针对上述问题,华为团队提出了一种高效的负载均衡策略OmniPlacement,通过专家重排、层间冗余部署和近实时动态调度,显著提升MoE模型的推理性能。
华为团队在研究中设计了一种基于层间非均匀冗余的优化方案,旨在以较低的显存开销实现高效的动态负载均衡和高鲁棒性。方案包含以下关键技术模块:
基于计算均衡的联合优化
通过分析专家激活数据,华为团队识别出高频调用的专家(热专家)和低频调用的专家(冷专家),并提出了一种基于计算均衡的联合优化算法OmniPlacement。该算法根据专家调用频率和计算需求优化部署顺序,显著降低负载不均现象。具体而言,该算法具有以下特点:
动态优先级调整:通过实时统计专家调用频率,动态调整专家的优先级和节点分配,确保高频专家优先部署在计算能力较强的节点上。
通信域优化:算法分析批次内激活卡数,优化跨节点通信域的范围,减少通信延迟。相比传统的静态分配方法,本算法显著降低了通信开销。
层间差异化部署:允许不同层根据负载特性设置不同的专家部署策略,支持非均匀冗余次数配置,从而更好地适应层间负载差异。
层间高频专家冗余部署
为缓解热专家的高频调用压力,华为团队还提出了一种层间专家冗余部署策略,通过为高频调用专家分配额外的冗余实例,降低跨节点通信开销,从而提升系统吞吐量。该策略的创新点包括:
动态资源分配:根据实时计算资源占用情况和专家调用频率,动态调整冗余实例的分配比例。系统通过预测模型提前分配资源,减少冷热专家间的性能差距。
层间差异化配置:不同层根据负载需求设置不同的冗余次数,增强对层间负载差异的适应能力。例如,高负载层可分配更多的冗余实例,而低负载层则减少冗余以节省显存。
预测性分配:结合历史激活数据和负载预测模型,系统能够提前优化资源分配,降低突发负载对系统性能的影响。
近实时调度与动态监控机制
为进一步提升系统的动态适应性,本研究设计了一套近实时调度与动态监控机制,具体包括以下子模块:
近实时调度:通过实时统计数据流特性,动态调整专家分配以适应输入数据的变化。调度算法能够在毫秒级时间内收敛到优化的静态专家部署模式,确保推理过程的高效性和一致性。该机制通过迭代优化专家分配,显著降低了动态调整的计算开销。
动态监控:实时跟踪专家激活数据和系统资源占用情况,为调度决策提供准确依据。监控任务在独立的计算流中运行,避免对推理主流程的干扰,保障系统整体效率。
动态专家权重访问与摆放:通过层间流水线设计,实现专家权重和分配的动态调整。系统在推理过程中并行处理权重更新和数据流分配,支持高效的专家动态摆放。流水线设计允许在不中断推理流程的情况下完成权重调整,显著降低高负载场景下的推理延迟。
上述机制通过高效的并行处理和快速收敛设计,显著提升了系统的动态适应能力和推理性能。特别是动态监控与调度分离的设计,避免了监控任务对推理延迟的潜在影响,进一步增强了系统的鲁棒性。
拥抱开源生态的开放实现
为支持上述技术的稳定运行,本研究开发了适用于vLLM的推理优化框架OmniPlacement,具有以下核心特点:
高兼容性:框架支持多种MoE模型架构,能够无缝集成到现有的推理系统中。
低时延开销:通过优化数据处理和调度流程,框架显著减少了额外计算开销,确保推理性能不受影响。
模块化设计:框架包含数据统计、算法运行和专家调度三大模块,各模块功能解耦,支持功能扩展和维护。模块化设计便于快速迭代和定制化开发。
可扩展性:框架支持动态添加新的负载均衡算法和调度策略,适应未来MoE模型的复杂需求。
OmniPlacement通过模块化架构实现核心算法与推理流程的解耦,为大规模MoE模型推理提供了可靠的基础设施。框架的设计理念是将负载均衡功能与推理主流程分离,从而在保证性能的同时提供高度的灵活性。
同时在OmniPlacement的开发过程中,华为团队也应用了业界很多已有的开源最佳实践,站在巨人的肩膀上,华为团队也会在近期全面开源OmniPlacement,回馈开源社区与开发者,为未来前行者在昇腾搭建更好的一个阶梯。
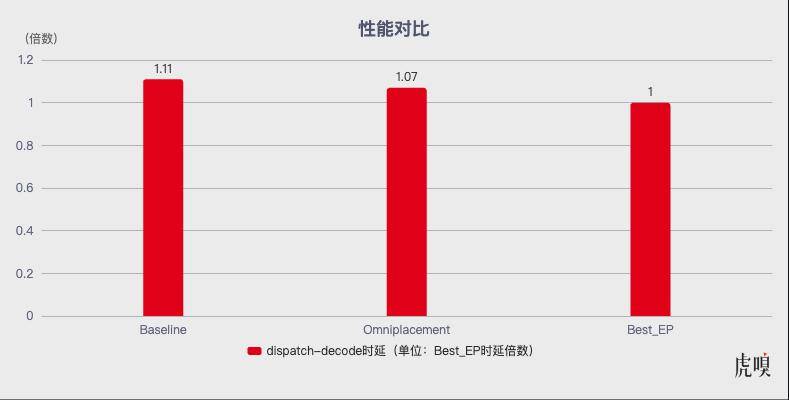 图:OmniPlacement与基线和BestEP的性能对比
图:OmniPlacement与基线和BestEP的性能对比
为验证OmniPlacement方案的有效性,本研究在DeepSeek-V3模型上进行了全面的实验测试,实验环境包括多节点GPU集群和高并发推理场景。测试结果如下:
推理延迟:相比基线方法(未优化负载均衡的MoE模型),推理延迟平均降低约10%。延迟的减少主要得益于动态专家分配和通信域优化,显著改善了用户体验。
吞吐量:系统吞吐量提升约10%,反映了资源利用率的显著提高。特别是在高并发场景下,冗余部署和动态调度有效缓解了负载瓶颈。
系统稳定性:在动态输入和高负载场景下,系统保持高效运行,未出现性能波动或服务中断。动态监控机制确保了系统对突发负载的快速响应。
进一步的分析表明,OmniPlacement在不同规模的MoE模型和输入数据分布下均表现出良好的适应性。实验结果验证了该方案在推理性能、资源利用率和系统稳定性方面的综合优势,为大规模MoE模型的实际部署提供了可靠支持。
写在最后
面向未来,华为团队进一步的研究将重点关注以下方向:
调度算法优化:开发更智能的调度算法,通过引入其他策略,进一步提升系统对复杂输入的自适应能力。
自适应专家选择:探索基于输入特征的自适应专家选择机制,动态调整专家激活策略,以应对多样化的推理场景。
框架扩展:扩展OmniPlacement框架的功能,支持更多类型的MoE模型,提升框架的通用性。
华为OmniPlacement 专家部署技术的发布,不仅是 MoE 模型推理性能的一次突破性提升,更标志着昇腾计算体系在 AI 算力领域的竞争力再攀高峰。这种技术突破背后,是华为长期深耕芯片架构、算法、软件生态与行业场景的厚积薄发。
 微信扫一扫打赏
微信扫一扫打赏
 支付宝扫一扫打赏
支付宝扫一扫打赏






