



编辑 |杨文
今天凌晨,大洋彼岸可真够热闹的。
OpenAI 推出了 GPT-4o 动嘴生图、P 图的功能,而谷歌则直接祭出了号称「最智能的模型」Gemini 2.5。
据谷歌首席科学家 Jeff Dean 介绍,首个版本 Gemini 2.5 Pro Experimental 已集成「思考能力」,是迄今为止性能最强大的 Gemini 模型,尤其擅长高级推理和编码,并在 @lmarena_ai 排行榜上拿下第一。

到底有多智能?
先来欣赏几个官方给出的 demo。
Prompt:p5js to explore a Mandelbrot set。
提示词:用 p5.js 探索曼德博集合。
Prompt:Create an animated bubble chart using Plotly Express of how economic and health indicators have evolved over the years for each continent.
提示词:使用 Plotly Express 创建动画气泡图,展示各大洲经济和健康指标随时间变化。
Prompt:Make me a captivating endless runner gameKey instructions on the screen. p5js scene ,no HTML. l like pixelated dinosaurs and interesting backgrounds.
提示词:用 p5.js 创作一个迷人的无尽跑酷游戏,画面上有关键操作提示。场景像素风,主角是恐龙,背景要有趣。
Prompt:Create a beautiful, interactive p5js demo (no HTML).l like fish and nebulaeShow me what the fish are thinking.
提示词:用 p5.js 做个好看的互动演示,别用 HTML。我喜欢鱼和星云,能不能展现出鱼的想法。
Prompt: p5.js (no HTML) swarm of 30 colorful boids swimming inside a rotating hexagon.like supernova nebulae.
提示词:用 p5.js 做一个无 HTML 的演示:30 只彩色的 “boids” 在一个旋转的六边形内游动,效果像超新星星云。
效果甚是惊艳。
而且谷歌一出手就是免费!
现在普通用户可以在 AI Studio 中免费使用 Gemini 2.5 Pro,Gemini App 中的 Gemini 高级用户也能使用它。
链接直达:http://aistudio.google.com/app/prompts/
一手实测
现在只要发布新模型,言必称自家的最智能、最强大,然后佐以各种跑分结果。
对于普通用户来说,分数、排名都不重要,真正重要的是,它在实际生活中到底好不好使。
既然谷歌称 Gemini 2.5 是目前地表最强,那我们就来场大乱斗,将它和 o3-mini、GPT-4.5、Claude3.7 Sonnet、Grok3、DeepSeek R1 拉出来同台竞技。
1. 一根 10 米长的竹竿能通过高 4.5 米、宽 3.8 米的城门吗?
如果按照常规的数学逻辑来思考,10 米长的竹竿确实无法通过这个尺寸的城门,但是在现实生活中,我们可以让竹竿与地面平行穿过城门。
万万没想到,这么一道简单的竹竿过城门,让这群曾号称最强的大模型全军覆没。
它们不约而同地想到了勾股定理,也把数值算对了,却忽略了现实是个三维空间。
来看看各家大模型的具体表现。
Gemini 2.5:
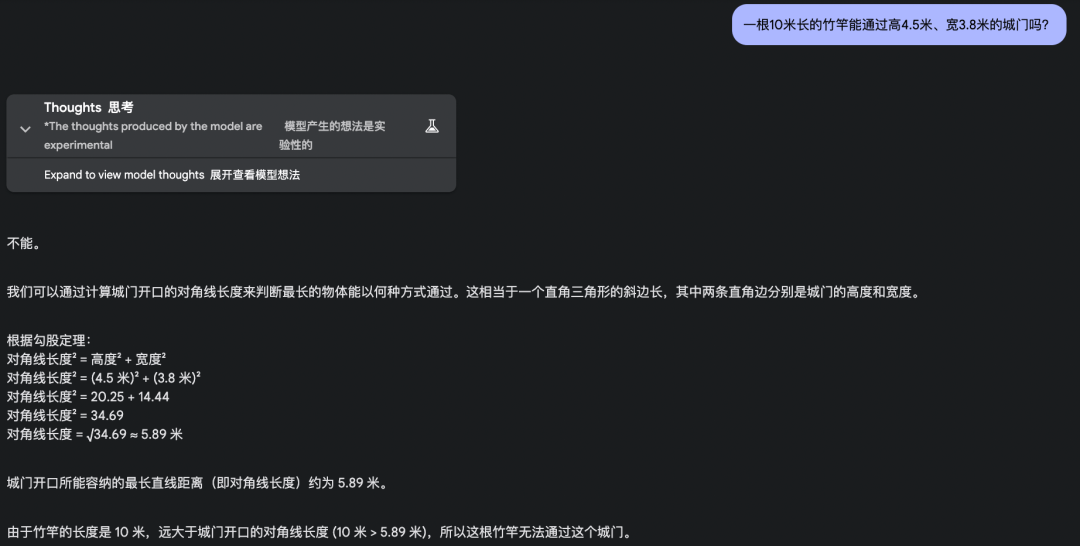
o3-mini:

GPT-4.5:

Claude 3.7 Sonnet:

Grok3:

DeepSeek R1:

2. 我有 6 个鸡蛋,碎了 2 个,煎了 2 个,吃了 2 个,最多还剩几个?
这道题目的关键在于理解这些动作之间的关系。
如果把每个动作视为独立事件,那将一个鸡蛋也不剩。
但题目问的是最多还剩几个,这表明可能有重叠的情况,碎的 2 个鸡蛋正好煎了、吃了,因此在最佳情况下,最多还剩 4 个鸡蛋。
Gemini 2.5 和 DeepSeek R1 思考一番后,抓住了问题关键,最终回答正确。
o3-mini、GPT-4.5 和 Claude3.7 考虑到了动作重叠的情况,但没有扣住「最多」这个条件,因此回答错误。
最搞笑的就是马斯克家的 Grok3,答案对了,但脑回路清奇,它是从完整的鸡蛋里拿出 2 个煎了、吃了,所以最后还剩 2 个完整的鸡蛋和 2 个碎鸡蛋。
来看看各家大模型的具体表现。
Gemini 2.5:
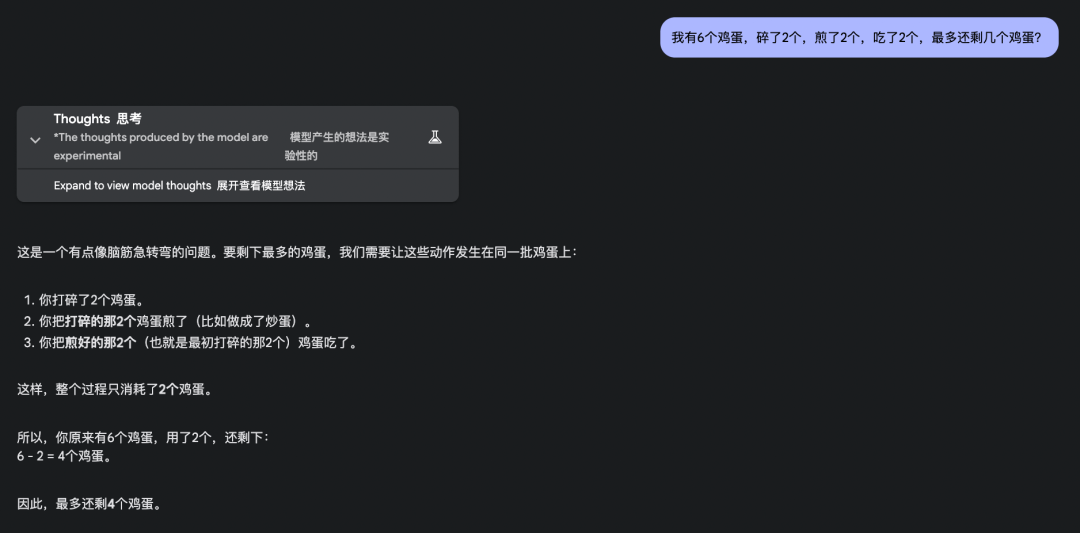
o3-mini:

GPT-4.5:

Claude3.7 Sonnet:
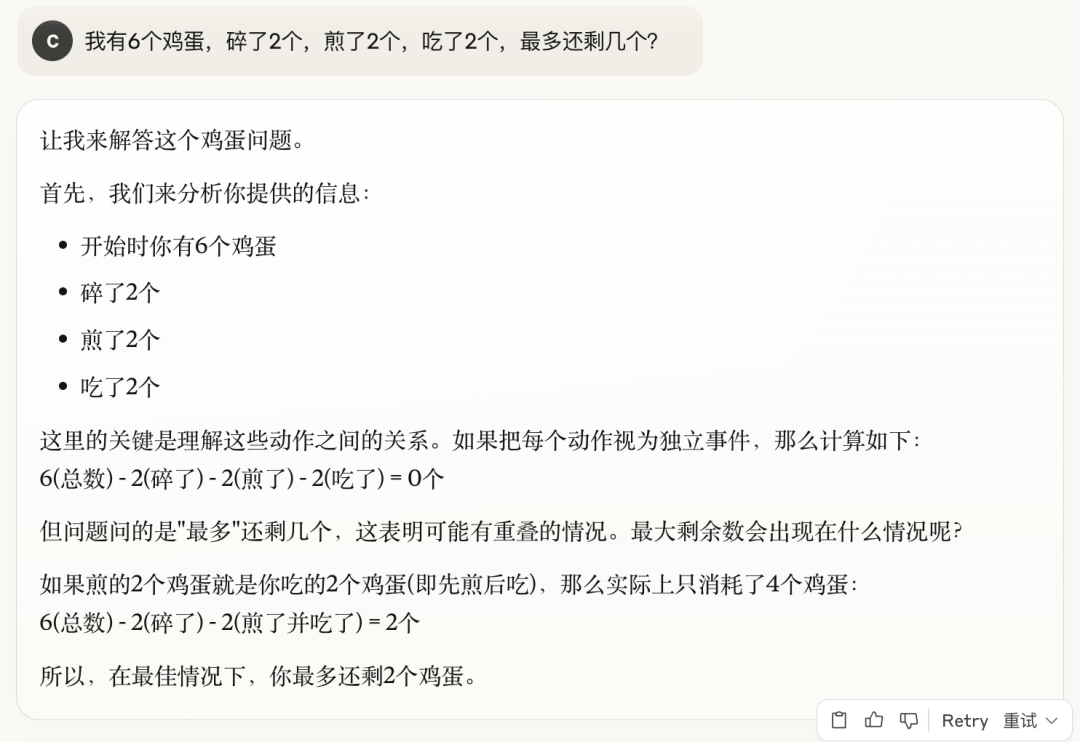
Grok3:

DeepSeek R1:

3. 两个人同时来到了河边,都想过河,但只有一条小船,而且小船只能载一个人。请问:他们能否都过河?
这道题目很容易让人陷入思维定势。
同时来到河边的俩人不一定在河的同一边,只要抓住这个关键点,这道题目就迎刃而解了。
Gemini 2.5、Claude3.7 Sonnet 思路清晰,回答正确。
o3-mini 和 GPT-4.5 虽然都说可以同时过河,但给出的解释非常牵强,GPT-4.5 甚至说让船空着漂回去,所以不算对。
Grok3 和 DeepSeek R1 则回答错误。
各家大模型具体表现如下。
Gemini 2.5:
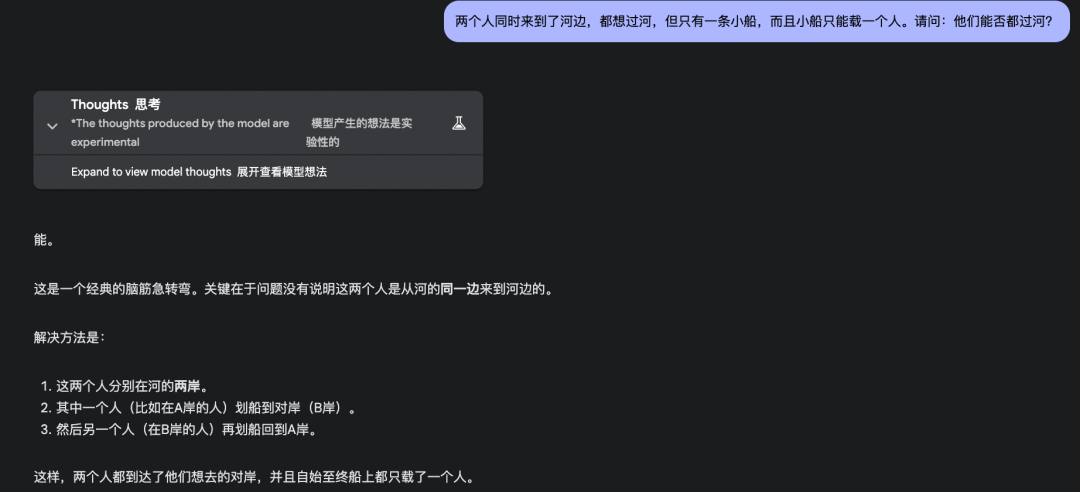
o3-mini:

GPT-4.5:

Claude3.7 Sonnet:

Grok3:
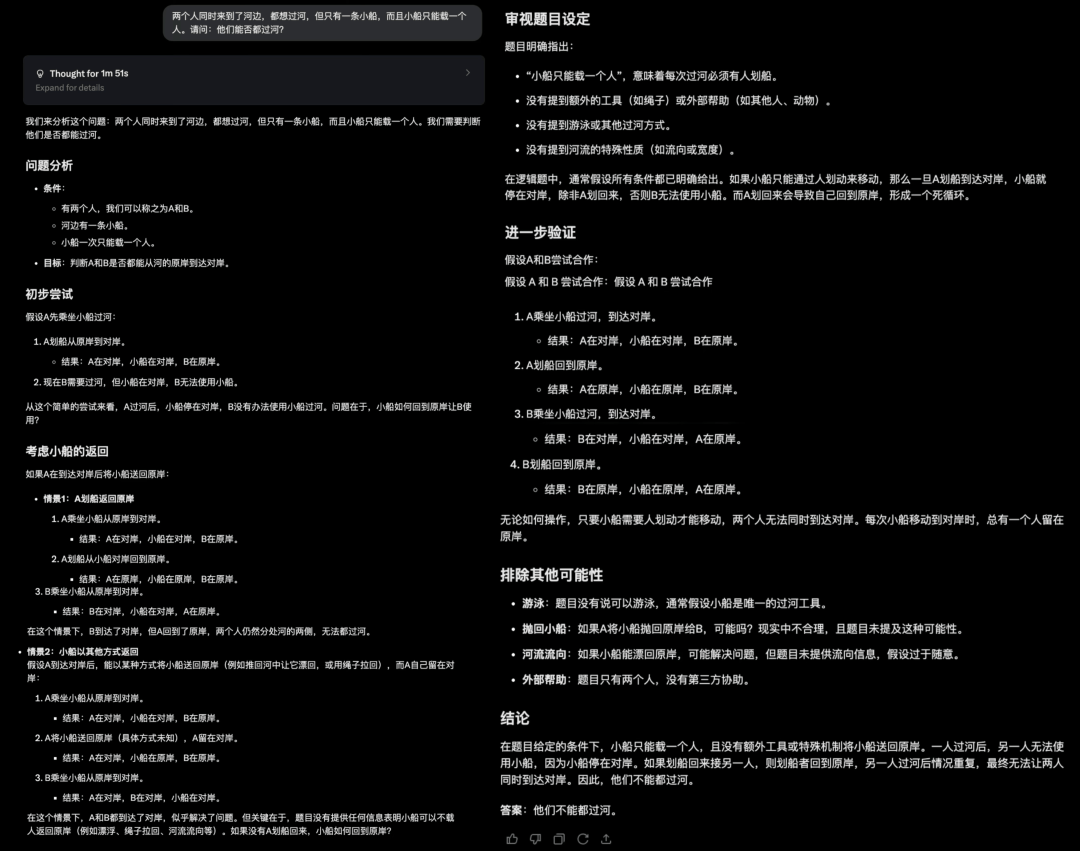
DeepSeek R1:

4. 张三去水果店买苹果,苹果进价为 20 元,卖价是 30 元。张三付给老板 100 元,老板没有零钱,就在卖鞋的人那里换了 100 元零钱,找给张三 70 元。后来卖鞋的人发现那 100 元是假币,于是找老板换回了 100 元。请问水果店老板损失了多少钱?
别看这道题目出现了如此多的数字,故事情节也曲折,但其实水果店老板损失的钱只有两部分 —— 苹果进价 20 元和找给买家的 70 元,因此答案时 90 元。
Gemini 2.5、Claude3.7 Sonnet、Grok3 和 DeepSeek R1 都回答正确。
o3-mini 和 GPT-4.5 纠结了半天,彻底被绕进去了,最终得出错误答案。
Gemini 2.5:
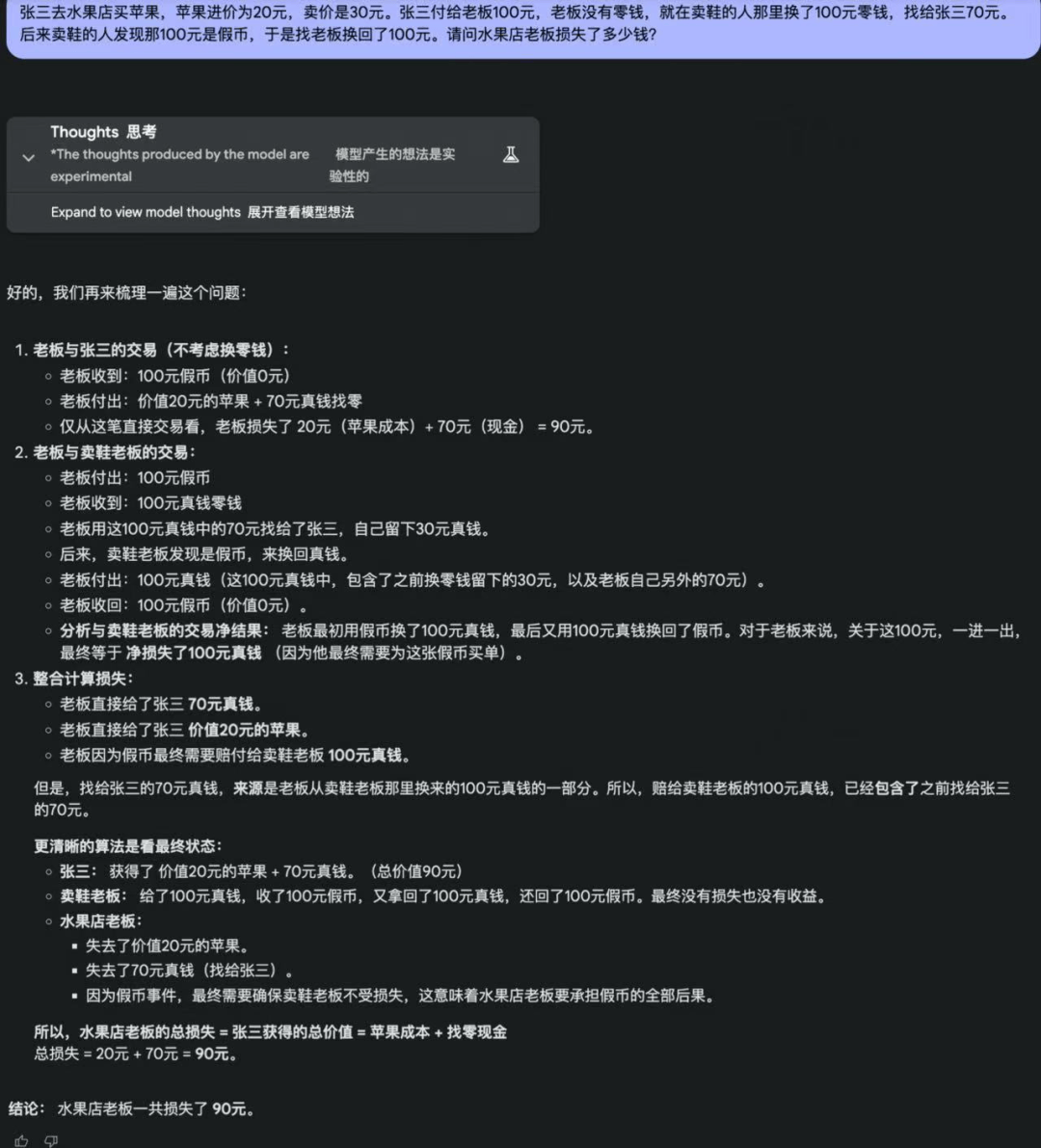
o3-mini:

GPT-4.5:

Claude3.7 Sonnet:

Grok3:

DeepSeek R1:

5. 多模态测试题,杯子有多高?
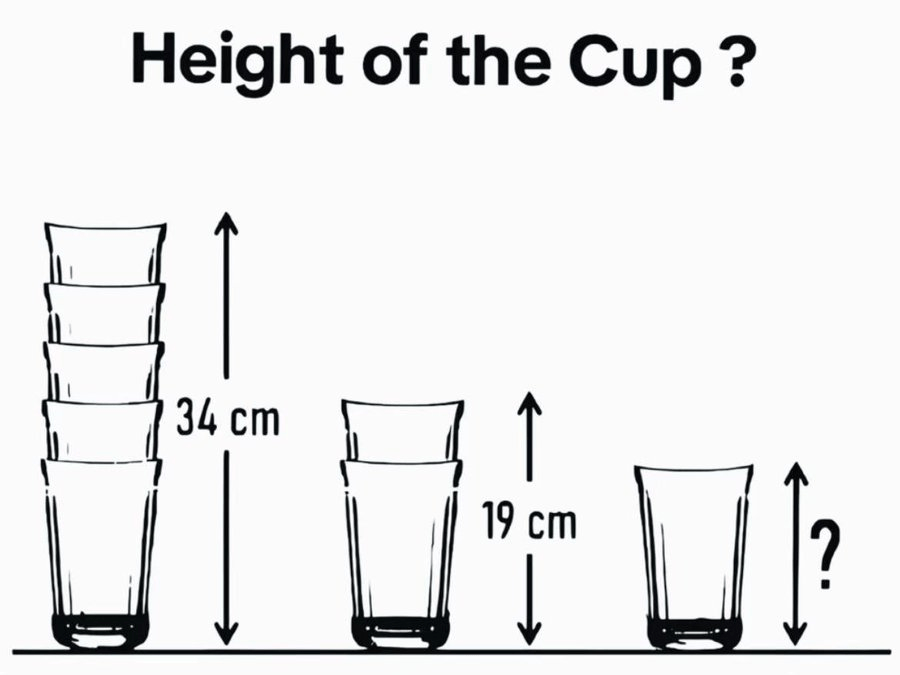
对于这道题,大模型们要先识别图像,然后进行计算。
Gemini 2.5、Claude3.7 Sonnet 和 Grok3 回答正确。
而 o3-mini、GPT4.5 全程胡说八道。
DeepSeek R1 虽然可以上传图片,但它只能识别图片中的文字,无法真正读懂图,因此回答错误。
各家大模型的具体表现如下。
Gemini 2.5:
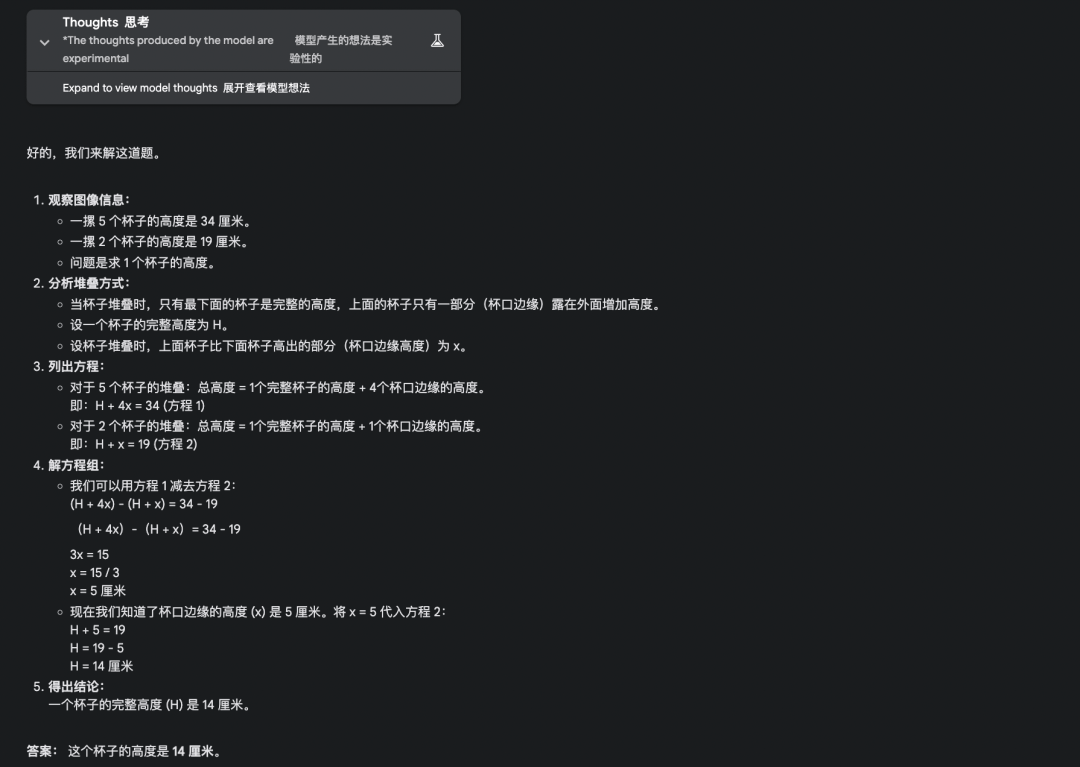
o3-mini:
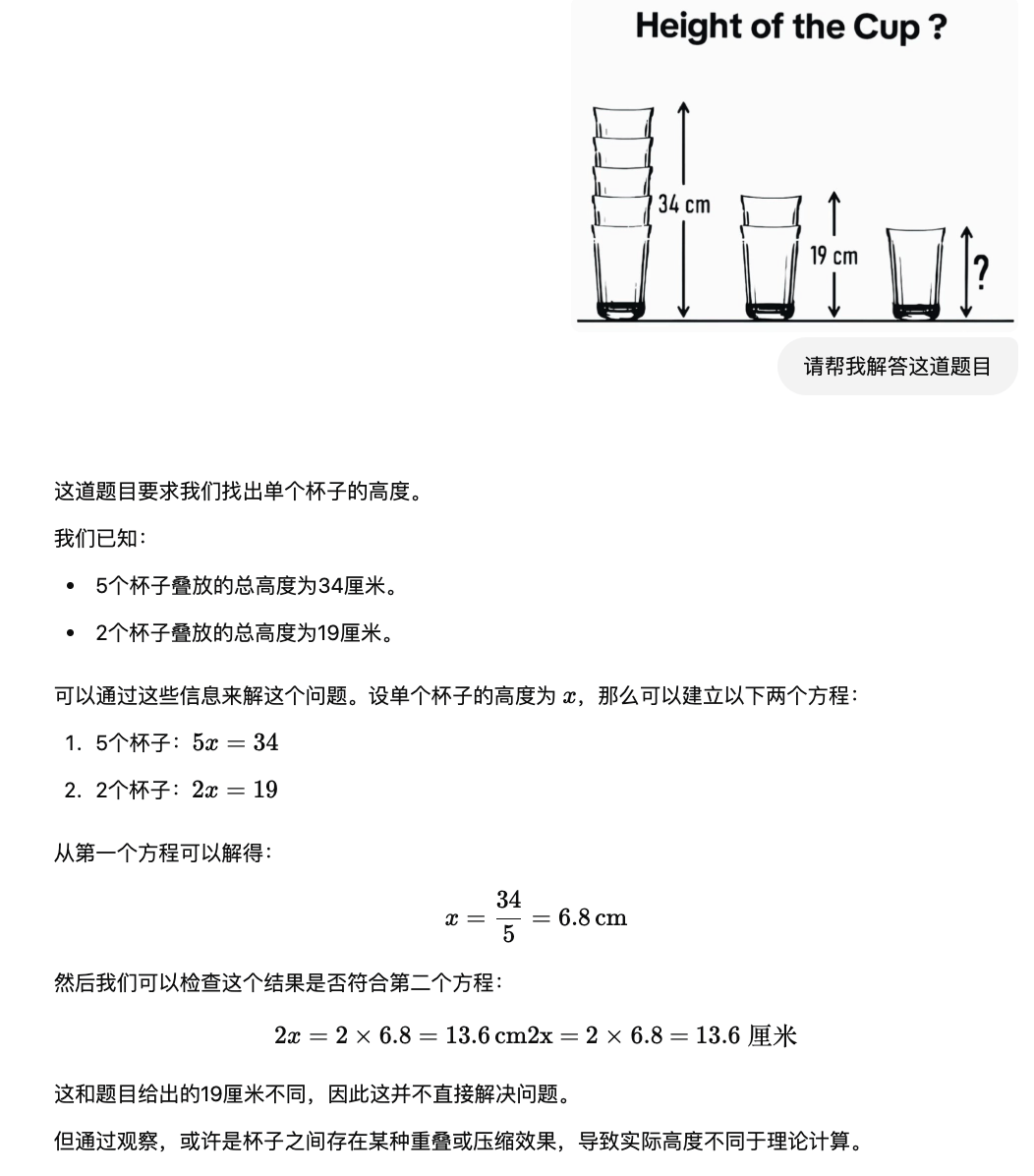
GPT-4.5:

Claude 3.7 Sonnet:

Grok3:

DeepSeek R1:

根据以上测试,我们发现 Gemini 2.5 虽然也会翻车,但正确率达 80%,总体来说数学逻辑推理能力还是挺能打的。
Claude 3.7 Sonnet 稍逊一筹,5 道题目错了俩。
最惨的就是 OpenAI 家的两大模型 o3mini 和 GPT-4.5,没有一道题目是做对的,正确率为 0。
以后我们会带来更多好玩有用的 AI 评测,也欢迎大家进群交流。
 微信扫一扫打赏
微信扫一扫打赏
 支付宝扫一扫打赏
支付宝扫一扫打赏






