


出品 | 搜狐科技
作者 | 梁昌均
编辑 | 杨锦
深夜放大招,这次OpenAI在图像生成上开始发力了。
3月26日凌晨,OpenAI宣布在ChatGPT和Sora中推出原生图像生成功能。这次,OpenAI CEO山姆·奥特曼也现身直播,称这是“最有趣、最酷炫的产品之一”和“巨大的进步”。
据介绍,OpenAI此次推出的图像生成功能,借助GPT-4o原生多模态模型,能够实现精确、准确、逼真的输出。
“我们一直认为图像生成应是语言模型的一项主要功能,因此我们将最先进的图像生成器集成到GPT-4o 中。”奥特曼表示,这意味着自由创作达到了新高度。
图像文本合体输出,多轮对话能保持一致性
奥特曼认为,图像生成已经出现一段时间,但它并没有发挥出真正的力量,在处理人们用于分享和创造信息的图像生成方面显得力不从心。
此次GPT-4o更新的图像生成功能在准确渲染文本、精确遵循指令,以及多轮对话保持一致性方面表现突出。
“一图胜千言,但有时在正确的位置生成几个词可以提升图像的意义。”GPT-4o可以将语言文字与图像结合,使图像生成成为一种视觉交流的工具。
根据将这句话分成七行,并让人物左右手分别拿有单词的指令,GPT-4o生成了如下照片,可以说精准完成文字在图像中的呈现。

在OpenAI的示例里,光影等细节也能在生成的图像中呈现出来,甚至还可以用它来画漫画。比如要求GPT-4o制作一幅四格漫画,四周留有一些边距,然后每格都有对应的文字内容。

可以说,GPT-4o最后生成的图片基本完成了指令的要求,尤其是漫画中对文字的输出基本没有错误,这下漫画师又要瑟瑟发抖了。

哪怕是文本内容非常多的菜单或者邀请函设计,同时对它的风格、背景等提出要求,GPT-4o也不在话下。

由于图像生成是GPT-4o的原生功能,还可以通过自然对话来进一步优化图像。它不仅能理解单轮对话,还能理解多轮对话,并在多次生成之间能够保持主体的一致性。
奥特曼在直播中就展示了这一能力,针对他和同事上传的自拍,要求GPT-4o转换成动漫风格,它则基本保持了每个人物的动作、手势、表情等特征。

接着,奥特曼要求在这张图像上加上“feel the agi”等内容,生成的图像三个人物主体基本保持了一致性,不细看的话感觉差不多(左边人物发型和脸部、中间人物眼睛和右边人物手势位置等出现一定变化),同时还对图片结构进行了主动调整,从横图变成了竖图。

再看一个更加复杂的示例,让GPT-4o详细解释牛顿三棱镜实验并生成信息图,它则结合自有知识库对具体原理进行了介绍。
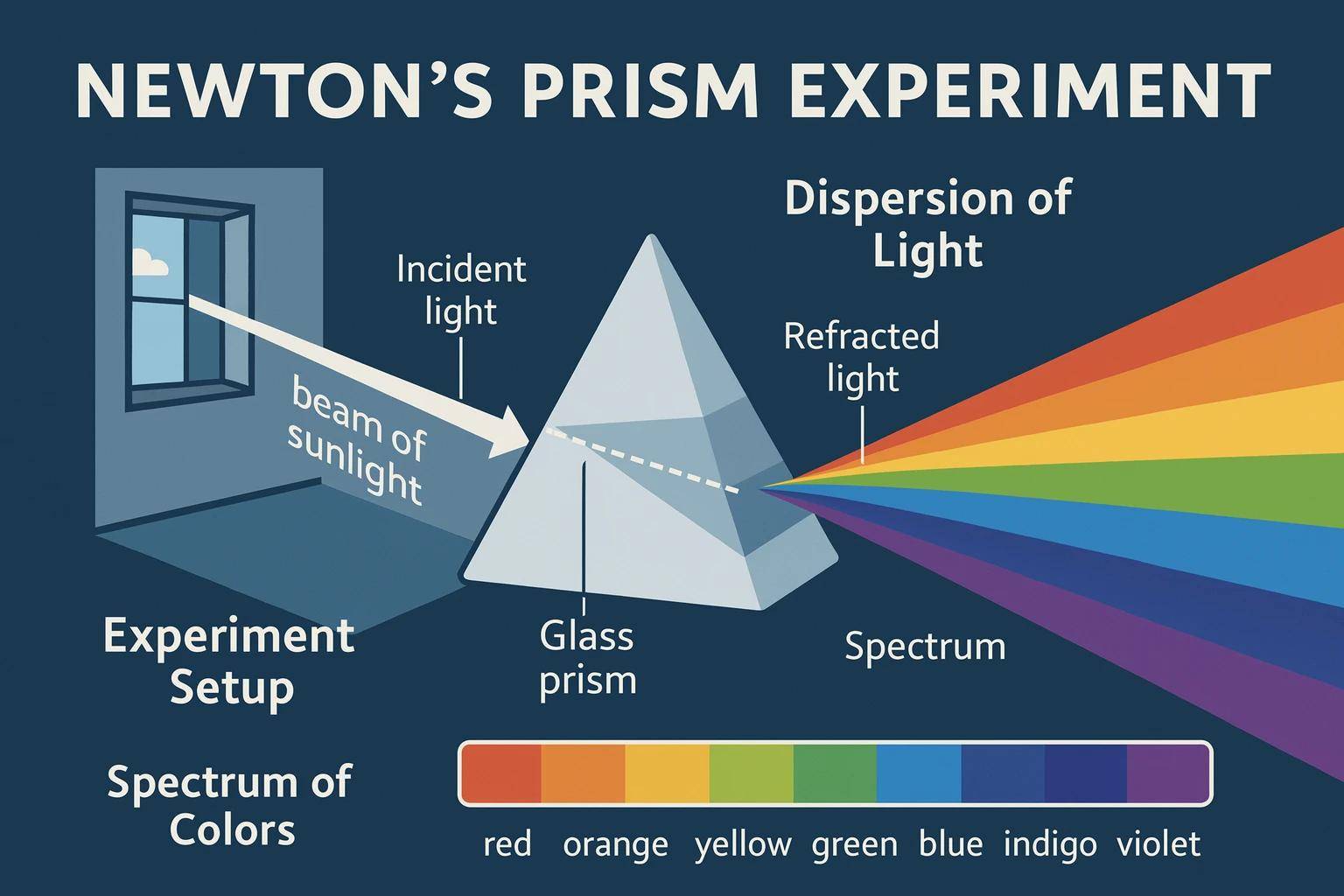
然后提出,生成一个人在在华盛顿广场公园的一张圆桌上,正在笔记本上画这个图的视角。前述那张信息图则到了这个人的手上,而且文本内容基本没有发生变化。

现在来“大变活人”,让牛顿上场。还是展示同样的场景,年轻的牛顿坐在桌子旁,拿着棱镜,演示实验,没有看到笔记本,GPT-4o再次按照指令完成了任务。

OpenAI还提到,其它模型在处理5-8个对象时会遇到困难,但GPT-4o可以处理多达10-20个不同的对象,且能体现对象与其特征的关系,使得控制更加精确,并呈现出细节。
比如酒杯里面的一滴红酒,GPT-4o生出来的图像看起来确实只有一滴红酒。对于数学方程的复杂描述,也能准确生成图像。
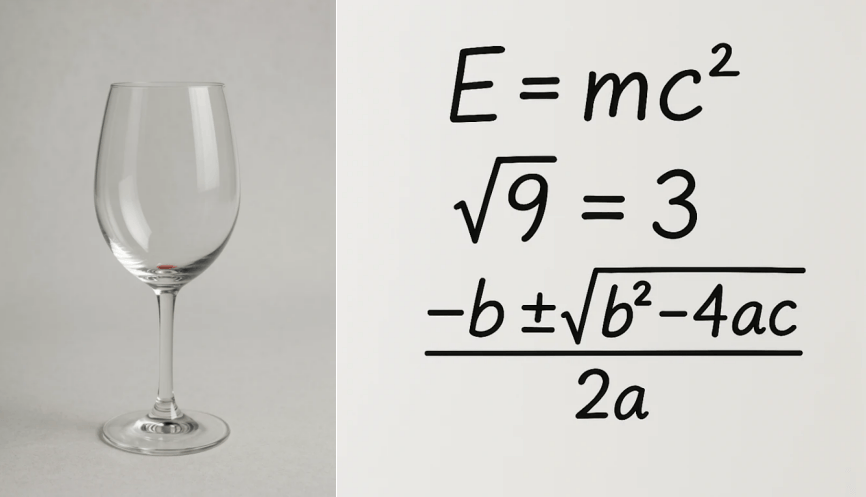
此外,GPT-4o还可以分析和学习用户上传的图像,将其详细信息无缝集成到其上下文中,为图像生成提供信息。OpenAI还强调,由于是在大量多样化的图像风格上进行训练,GPT-4o生成的图片逼真度和风格更为自然。

奥特曼表示,GPT-4o的图像生成能力得益于用全模态模型进行训练。“它不仅是一个语言模型,还是一个图像、音频等所有模态的模型,可以理解和生成,可以在模态之间无缝切换。”
具体来说,OpenAI根据图像和文本的联合分布对模型进行了训练,不仅学习了图像与语言的关系,还学习了图像之间的关系。同时,结合后训练,使得最终模型具有不错的视觉流畅性,并能够生成有用且上下文一致的图像。
免费用户要再等等,OpenAI多模态融合向前一步走
GPT-4o图像生成功能将从今天开始将作为ChatGPT中的默认图像生成器推出,优先每月200美元的Pro订阅用户,并在不久后提供给Plus和免费用户、企业用户和开发者。
同时,它也可以在Sora中使用。此前,OpenAI专门推出了图像生成应用DALL·E,而这款产品的用户同样也可以通过专用的DALL·E GPT访问。
这意味着,ChatGPT在多模态融合趋势方面又向前迈出了一步,此前大家对它的认知多是对话式的语言聊天工具,现在它已经具备音视频对话、图像理解和生成等多模态能力。
“随着我们的模型越来越强大,它对世界的了解也在加深。此前只能通过文本或代码来表达,现在这些模型可以将所知道的内容可视化,并以视觉方式呈现出来。”奥特曼说。
他希望,ChatGPT将向每个人提供创建工作图像的能力,让人们能够创造他们需要和想要的东西,使其不仅成为想象力的工具,也成为学习和交流的工具。
“这代表OpenAI正在朝着真正的多模态模型迈进,ChatGPT可以做一切事情,并给了用户更多的控制权。”奥特曼表示,“这代表我们在允许创作自由方面达到了新的高度”。
但从OpenAI的直播演示来看,图像生成等待的时间会比较长,往往需要长达一分钟,甚至更长时间。“我们的模型并不完美,目前存在多个限制,我们将通过模型改进来解决这些问题。”OpenAI表示。
“我们希望该工具不会创造令人反感的东西,将知识自由和控制权交到用户手中是正确的做法,但我们会观察进展并倾听社会的声音。”奥特曼还呼吁,为AI设定非常宽泛界限是正确的,而且随着越来越接近通用人工智能,这一点变得越来越重要。
在安全标准方面,OpenAI发布了多项举措。GPT-4o生成的图像会具备C2PA标示,这将识别图像是否来自GPT-4o,并构建了内部搜索工具,以验证内容是否来自该模型。同时,开发推理模型,对文本和输出图像进行审核,以符合政策。
目前,多模态融合是大模型发展的趋势之一。随着OpenAI在图像理解和生成层面完成布局,下一步可能就是集成Sora,实现视频的理解和生成的大一统。
此前预告的GPT-5作为融合大模型,是否会在多模态层面实现完整布局,又是值得期待的更新了。
 微信扫一扫打赏
微信扫一扫打赏
 支付宝扫一扫打赏
支付宝扫一扫打赏






