


(图片来源:钛媒体AGI编辑林志佳拍摄)
“我原以为AI六小虎是为大厂探路,没想到如今,其实连大厂都在给DeepSeek探路。”梅花创投创始合伙人吴世春近期在清华大学举行的一场演讲中表示,不只是 AI 六小虎公司,很多“独角兽”中的独角“猪”融了很多钱,但没有造血能力。
回顾2024年的3月,月之暗面(Moonshot AI)、智谱、百川智能、MiniMax、零一万物、阶跃星辰这“AI 六小虎”发展如火如荼,当时月之暗面的kimi智能助手迎来了一波好评热潮,智谱大喊全面对标OpenAI,王小川还在讨论要做Super App杀手级超级应用。
但仅仅过了360多天后的今天,开源 AI 模型DeepSeek热潮席卷全球,用7天完成了1亿用户的增长。随后,百度、腾讯等多家互联网大厂和中小企业、政府机关开始接入和适配DeepSeek。
如今,“AI 六小虎”被视作受这一轮热潮冲击最为显著的代表,已然踏上“分化”之路,各自在收缩业务战线、探索盈利途径:百川多名联合创始人离职,并选择深耕医疗To B领域;零一万物则不在研发万亿规模超大参数模型,转而拥抱DeepSeek;MiniMax削减B端投入,将发展重心转移至模型和C端应用;智谱则在短短93天内公布48亿元融资,为自身发展“冬储”能量。
管理咨询机构Roland Berger指出,中国AI应用中,字节豆包、DeepSeek已成为超级入口。今年2月数据显示,豆包和DeepSeek与第三名Kimi的月活规模差距扩大至3600万,而部分新晋者如腾讯元宝凭借接入DeepSeek模型的流畅体验,积极投流,在短时间内也实现了显著增长。然而,文小言、智谱清言等“老牌”AI助手因增速不及,面临不进则退的挑战。
零一万物创始人兼CEO李开复3月21日表示,DeepSeek掀起的行业变革彻底颠覆了 AI 行业发展模式,可能让OpenAI创始人辗转难眠。他预测,中国市场最终可能只剩下DeepSeek、阿里巴巴和字节跳动三家主要的AI模型公司,其中DeepSeek目前势头最强。
李开复强调,中美两地的投资人几乎不再下注更多更贵的底层模型公司,他们更愿意投资AI应用、消费者应用、AI基础设施类型的创新企业。

中国“AI六小虎”融资信息统计(数据仅供参考)
进入AI大模型下半场,形势已然明朗。
尽管DeepSeek讨论热度渐趋下降,但阿里、腾讯、字节等大厂凭借自身全方位的资源投入,向“AI六小虎”彰显出一个残酷现实:百度CEO李彦宏所预判的“99%的AI公司会在泡沫破裂时面临倒闭风险,仅有1%的公司能够存活”正逐步成为现实。
DeepSeek之后,六小虎从追基模转向“求生存”
“虽然对AI来说是重要的进步,但还算不上革命,”TrueAGI 和人工智能超级联盟ASI Alliance首席执行官 Ben Goertzel 博士指出,DeepSeek带来了AI技术的“寒武纪爆炸”,表明更少的计算能力就能实现AGI(通用人工智能)。
DeepSeek于2024年12月发布了处理语言、运行对话应用的基础模型V3,并于2025年1月开始提供具有强大推理功能的R1模型。DeepSeek之所以爆火,原因在于R1模型在更低成本与开源生态的基础上,多个关键任务层面展现出与美国OpenAI o1等顶尖闭源模型相匹敌,甚至更优的性能。
美国风险投资家Marc Andreessen表示,DeepSeek模型是 AI 的“斯普特尼克时刻”,即是20世纪50年代末苏联卫星发射,开启太空竞赛的时刻。
DeepSeek披露过几个关键数据:V3训练成本仅花费560万美元,V3/R1模型理论一天的总收入达到56.2万美元(约合407.41万元)、成本利润率高达545%。
然而,大众对DeepSeek的成本估算存在分歧。其中,Meta前工程师表示,560万元不包括算力运营、数据中心服务等费用,这些算力服务成本更加高昂,至少需要花费数亿美元。
PPIO派欧云联合创始人兼CEO姚欣近期独家对钛媒体AGI表示,545%只是理论数据,不代表行业趋势。“如果全行业545%,大家都别干了”。他强调,这份没有收入起伏的数据,证明了DeepSeek全天近16个小时都是在峰值期,没有办法完整地满足用户的请求和服务,这样的服务质量是“不及格”的。
不过,这些都无法阻挡拥抱DeepSeek热潮。
当下,微软、英伟达、亚马逊、英特尔、AMD等全球科技巨头相继宣布上线了DeepSeek开源模型推理服务,国内厂商诸如腾讯云、阿里云均支持DeepSeek的一键部署和调用,腾讯微信、浏览器、元宝、小红书等多款国民级产品接入DeepSeek,涵盖社交、云服务、办公、地图等领域。
据钛媒体AGI统计,目前已有超过300家企业接入了DeepSeek。
但DeepSeek并没有让算力需求消失。今年GTC大会上,英伟达创始人兼CEO黄仁勋表示,Meta、亚马逊、谷歌和微软前四大云服务商去年购买了130万颗的H系列芯片,今年则是要购买360万颗BlackWell芯片——但芯片行业人士指出,最终出货的系统数量其实并没有增加多少,这是黄仁勋的“单位换算”文字游戏。
黄仁勋认为,从两年前的ChatGPT到如今DeepSeek引发的推理能力,Scaling Law(规模定律)并没有消失,而是从一个变成了三个——预训练扩展、在代理人工智能(Agentic AI)阶段的后训练扩展,如今的算力需求已比去年预估的规模高出100倍。
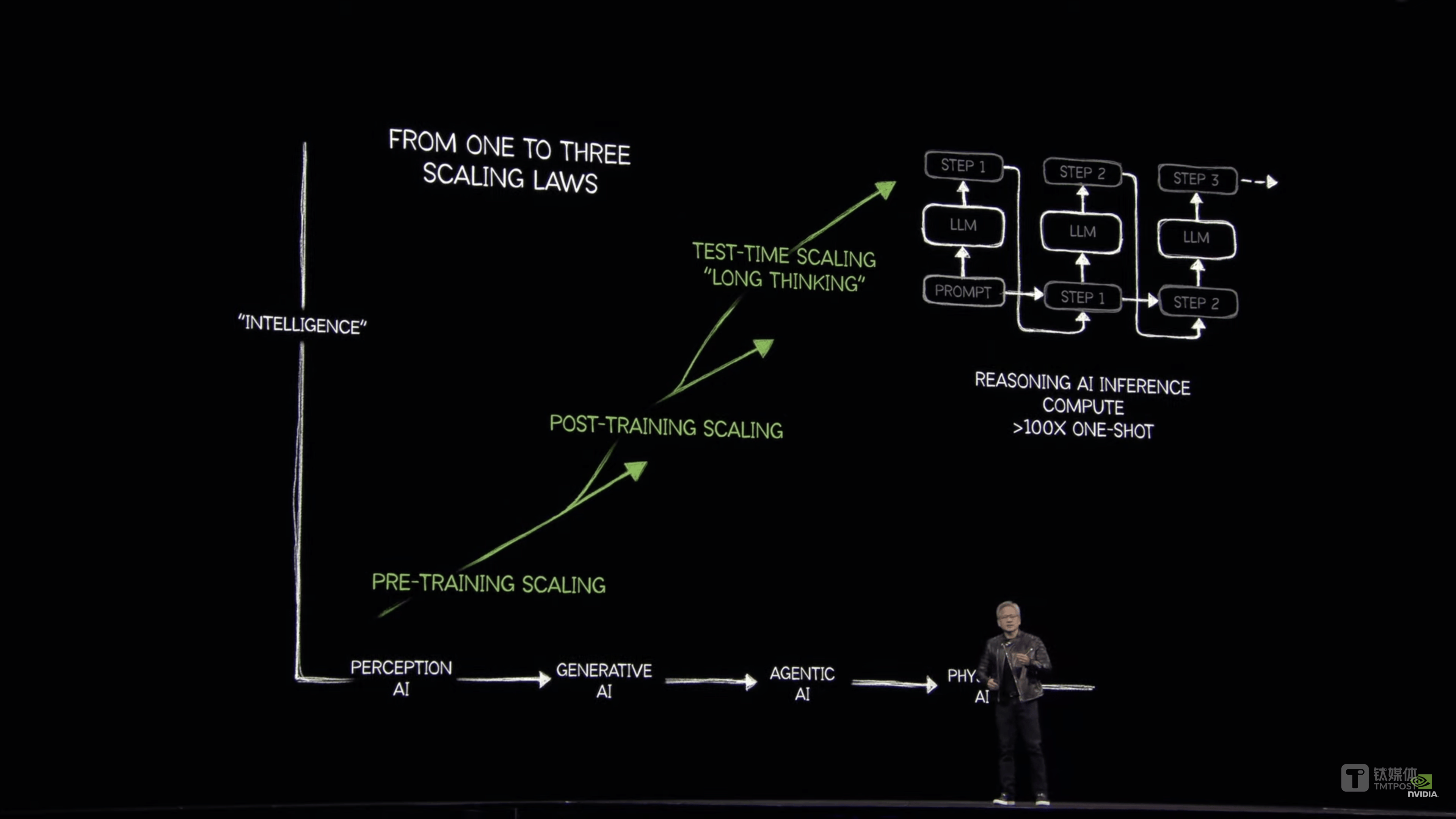
然而,大会当日英伟达收跌3.4%。华泰证券最新研报称,R1等推理模型和传统的大语言模型相比,所需要生成的token量接近传统大模型的20倍。此次GTC上,虽然英伟达也提出了后训练Scaling和测试时间Scaling的叙事,但从英伟达当天股价表现上来看,此次GTC或未能打消投资人在算力需求增长方面的担忧,同时英伟达的GPU方案能够胜出目前还不确定。
如今,“AI六小虎”面临着复杂严峻的局面。DeepSeek开源模型正处于如日中天的发展态势,影响力持续扩张。与此同时,行业内训练成本与算力成本不断攀升,“烧钱”规模远低于大厂,这让“AI六小虎”收入微薄却深陷高额亏损的困境。
也正因如此,今年,“AI六小虎”不得不陆续放弃对基座模型的追逐,转而将重心调整为“求生存”,努力在艰难的市场环境中探寻可持续发展之路。
- 百川智能:缩减对预训练大模型的投入,今年将逐渐加大对医疗增强大模型的倾斜。3月20日,百川智能与北京儿童医院、小儿方健康共同发布全球首个儿科大模型“福棠·百川”儿科大模型。此外,仅3月,百川就从裁金融组团队,到百川联合创始人焦可、联合创始人陈炜鹏陆续离职,此前百川智能联合创始人、商业化负责人洪涛已于去年离职。
- 零一万物:推出万智企业大模型一站式平台,为企业级DeepSeek部署定制解决方案,内置DeepSeek V3/R1等平台。李开复回应钛媒体AGI等:公司未来不再做单一大模型,而是采取模型开放策略,研发能够兼容适配国内主流模型的产品,转型之后,零一万物从基座大模型重投入调整为软硬件解决方案提供商,不再训练万亿参数规模的超大基模,但仍会继续做轻量化模型。
- 智谱:一面融资、一面转Agent和大模型落地。仅在3月内,智谱便先后宣布获得杭州国资、珠海华发集团、四川成都高新区18亿元融资,合作搭建首个城市级GLM大模型空间“智谱+珠海华发空间”、联合打造四川省基座大模型“智谱诸葛大模型”以及AI基础设施等。
- MiniMax:在收缩B端业务后,持续投入视频生成、视觉多模态与海外产品,包括万卷等多款App停止更新、海螺整合成MiniMax,统一力量发力AI应用落地。此外,有消息称MiniMax还在讨论收购深圳AI视频生成创企鹿影科技(Avolution.ai),后者对外发声想要尽快被高价收购。
- 月之暗面:大幅收缩产品投放预算,逐渐披露在长文本与开源技术方面的进展,并且与“豆包”一样的界面加速迭代kimi智能助手,满足市场对 AI 应用的需求。
- 阶跃星辰:开源图生视频模型——Step-Video-TI2V,基于30B(300亿)参数Step-Video-T2V训练的图生视频模型,支持生成 102 帧、5 秒、540P 分辨率的视频,具备运动幅度可控和镜头运动可控两大核心特点,同时天生具备一定的特效生成能力。同时,跃问AI拥抱DeepSeek,并重点推进智能车、手机终端、金融、机器人等领域的 AI 大模型技术落地。
总的来看,除了MiniMax、月之暗面之外,剩下四家大模型公司都希望在To B企业端实现更大的收入增长,并且希望用 API 接入方式,代替传统 AI 软件的“定制化”需求。
李开复对钛媒体AGI表示,公司已经全面转向应用阶段,2025是Al-First应用爆发年,也是大模型商业化的大考年,而AI需要市场,市场也需要 Al,行业亟需“性能x性价比”最优解。
“今天,大模型我们走(发展)了两年多,2025年最重要的事件是开源力量+中国实力,DeepSeek的横空出世,不但是中国的骄傲,而且也带来了更加清晰的终局,也就是开源必将胜出,大模型的格局将从拼比底模的技术指标,走向拥抱开源模型的商业赋能,那么中国就有超大市场、超多场景。”李开复称,未来的大模型的行业竞争将不再单指模型性能的比拼,更关乎从中台到应用的能力,即模型能否快速响应场景需求、基于中台构建行业应用。
然而,企业借助To B端服务实现扩张后,能否持续生存,目前仍存疑。依图科技联合创始人林晨曦对钛媒体AGI表示,如果在To B端,医疗 AI 对于大模型六虎并不一定是正确的方向,医疗AI行业订单的客单价很薄,收入和投入不成正比,几乎还是死路一条,医疗AI行业的商业环境本质上没有什么变化。
钛媒体AGI从行业人士处获悉这样一个案例。北京一家公立医院计划借助 AI 大模型,结合 CT / 核磁共振等现有技术,直接精准观察肿瘤病灶位置,该医院要求颇高,却将成本压得极低。字节、百川等企业参与了此次竞标。
最终,字节经评估认定,以当前技术水平,无法达到医院所期望的要求,况且订单价格过低,连成本都难以覆盖。但出人意料的是,百川却选择与医院展开合作。一位参与竞标的人士向钛媒体AGI透露,“连我们这些大厂都觉得难以实现的方案,百川就算拼尽全力、耗尽资源去做,最终也很难获得可观的收入 。”
此外,这些 AI 公司内部管理存在严重问题。比如北京的一家 AI 公司办公区,有一层颇为特殊。与其他楼层不同,这一层全是实习生,却能享受诸如午餐、零食等优渥待遇,而其他楼层的员工则无此福利,不仅如此,公司内部的采购部门和商务销售部门矛盾频发,冲突不断,同时公司不断调整商业化方向,导致收入低于预期。
另一家北京的 AI 公司,其内部情况错综复杂,该公司的一位创始人行事风格独断,将CEO管理的诸多人员全部辞退,唯独留下自己人,致使公司CEO被“架空”,沦为有名无实的“吉祥物”。同时,在技术与产品层面,该公司状况堪忧,其自研基座模型被舍弃,小模型和产品服务在市场上毫无竞争力可言,然而公司仍硬着头皮大力开展推广销售工作,究其背后原因,创始人的最终目标是自身影响力变大,并且能将公司高价“变卖”给大厂。
显然,国内 AI 公司的扩张和“派系”背后,仍有很多隐忧无法消弭。
“这些‘大模型六虎’正在以三倍速,走当年我们‘AI四小龙’(依图、旷视、云从、商汤)2017-2019年的老路。”林晨曦对钛媒体AGI表示,如果 AI 创业公司想在国内 C 端产品中获得商业化,能力和最终结果远不及字节等互联网大厂,后者有大量的投入、人力资源、流量与用户规模,这是创业公司无法做到的。
追逐OpenAI,奥尔特曼暗示GPT-5将免费提供
如今,阿里、腾讯两家互联网大厂都已经决定向 AI 技术领域加大研发投入。
其中,阿里巴巴集团CEO吴泳铭已经宣布,未来三年,阿里将投入超过3800亿元,用于建设云和AI硬件基础设施,总额超过去十年总和。这也创下中国民营企业在云和AI硬件基础设施建设领域有史以来最大规模投资纪录。
而腾讯2024年研发投入达706.86亿元,年度资本开支更突破767亿元,同比增长221%,创历史新高。其中,AI项目发展所涉及的资本开支就达390亿元。腾讯总裁刘炽平表示,腾讯计划2025年进一步加大资本开支,预计会占2025年总收入的“低两位数百分比”。这意味着,2025年腾讯的资本开支可能接近1000亿元的水平。
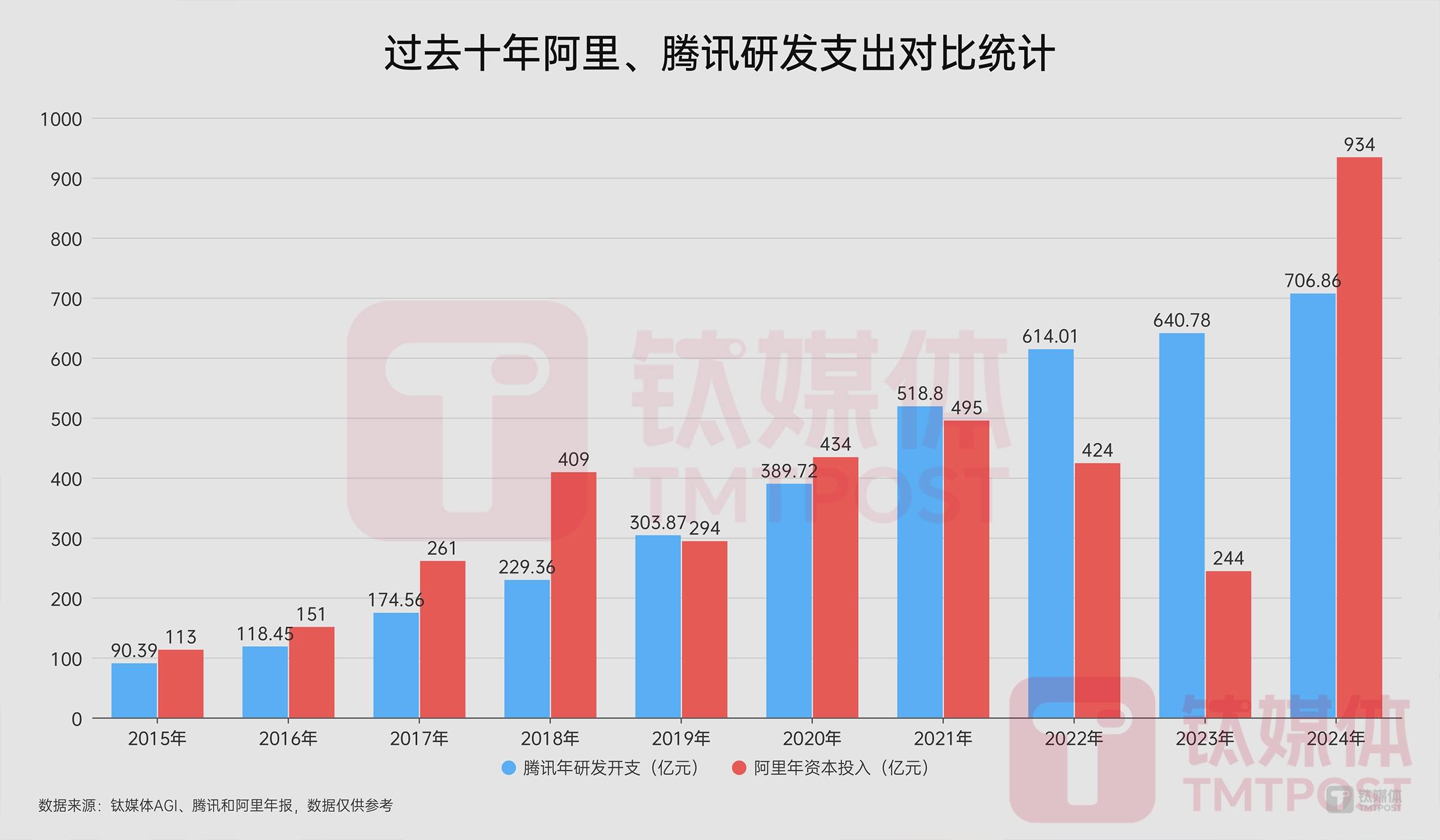
据钛媒体AGI统计,过去十年,阿里、腾讯的研发支出各不相同,腾讯稳步提升,阿里的研发投入则随着业绩而变化,并在2024年达到最高的934亿元。
“AI爆发远超预期,国内科技产业方兴未艾,潜力巨大。阿里巴巴将不遗余力加速云和AI硬件基础设施建设,助推全行业生态发展。”吴泳铭表示。
事实上,DeepSeek热潮让国内投资界人士、政府机构都变得异常活跃,转向了“中国 AI 能力赶超美国”的叙事逻辑中,而中国是否已经在AI领域“弯道超车”,也引发热议。
对此,清华大学计算机系副教授刘知远表示,“AGI新技术还在加速演进,未来发展路径尚不明确。我们仍在追赶阶段,已经不是望尘莫及,但也只能说是望其项背。在别人已经探索出来的路上跟随快跑是相对容易的,接下来我们要面对一团未来迷雾。”
事实上,DeepSeek的创新,很好地说明了什么叫“需求是创造之母”。
这轮热潮带有一些无奈的色彩,DeepSeek在算法、架构、工程方案的创新方案,核心因为算力被卡住,所以这样的方案几乎只有可能在中国公司出现,因为只有中国公司才会同时面临“巨大需求和巨大限制”这两个问题。因此,DeepSeek的创新在中国以外也是很难复制的。
DeepSeek这家中国本土的团队,因为其意外争气的表现,拉动了市场对于“中国AI”想象,相应地中国科技公司也都是“与有荣焉”,努力以各种各样的方式赶上这波流量。
腾讯集团高级执行副总裁、云与智慧产业事业群CEO汤道生认为,AI行业还处于早期阶段。大家都在跑马圈地,尝试着不同的商业模式。有的在追Scaling Law,有的在打造To C市场新入口,有的在做产业落地,非常热闹。
“AI正在跨过产业化落地的门槛,站在普及应用的全新节点上。行业由之前的模型训练主导,发展到今天更多是应用与Agent驱动;我们看到,云上DeepSeek API调用量激增,语音交互的需求也带动了ASR(自动语音识别)与TTS(文本转语音)模型的API调用;模型推理的算力消耗正在高速增长,规模化推理的成本优化,成为云厂商的核心竞争力。”汤道生说。
无论是从 “AI 六小虎” 离职的高管,还是大厂出身及科学家转型的 AI 创业者,在创业早期,都在思考如何兼顾收入与AGI发展这“双重目标”。这情形就像,火锅店大师傅刚调好秘制底料,后厨的二把手、三把手便带着徒弟另起炉灶,分别去开串串香店和冒菜馆。商业江湖从不缺新风口,AI 大模型赛道才刚起步,那些本应专注于此的 “掌勺人”,却已被隔壁“烧烤摊”的香味吸引,蠢蠢欲动。
在金沙江创投主管合伙人朱啸虎看来,目前市场已经没必要去关注“AI六小龙”了,创业公司做底层模型已经毫无意义。未来基础模型的竞争格局内,大厂中只会留下阿里、腾讯、字节这三家。至于创业公司,朱啸虎认为必须找到自己的根据地,才有机会异军突起,但从现状来看,他认为还没有看到能够颠覆阿里、腾讯、字节的万亿美元机会。
李开复认为,中美市场中的超大模型预训练正在逐渐寡头化,并且寡头化的程度在不断加大,其中开源圈展现出压倒性的优势。美国市场中,OpenAI和Anthropic都相信自己还能训练出远超其他玩家的闭源模型。但从结果来看,OpenAI在2024年的运营成本为70亿美元,而DeepSeek的运营成本可能只有OpenAI的2%。
“有了这样一个强大的竞争对手,我认为OpenAI CEO奥尔特曼(Sam Altman)可能夜里辗转难眠。”李开复表示。
从技术角度,各家模型优势各异,但DeepSeek将成本低数倍的开源模型免费推向市场,已经有效地将计算成本降低了五到十倍。而开发最尖端AI的过程中,丰富的计算资源仍然是强有力的武器。
其中,由马斯克领导的美国xAI于2月17日开始提供的新AI模型Grok 3系列,其在数学、科学和编程能力方面超过了竞争对手,主要因为大幅扩建数据中心,拥有30万英伟达显卡进行训练,比此前模型计算能力大10倍以上。
如今,OpenAI的战略方向发生转变,不再一味执着于大模型本身的研发推进,而是将工作重点转移到了ChatGPT应用的用户增长层面,全力拓展用户规模。
奥尔特曼表示,未来五年,拥有十亿活跃用户的网站更有价值,同时,AI战略优势将体现在软硬件的完整生态、实现最经济和最充足的推理能力,以及持续进行前沿研究保持开发出最优秀模型。
随着今年2月底训练数据量高达120万亿tokens的规模最大、知识储备最丰富模型GPT-4.5发布,AI 模型竞争进入“白热化状态”。OpenAI计划在数个月内公开的基础模型“GPT-5”不仅具备知识能力,还具备高度的推理能力。合并后的AI预计变得庞大,因此需要大量的最高性能GPU。
奥尔特曼认为,AI 是能够实现真正创造力的基础。他暗示,OpenAI正在重新考虑其封闭战略,GPT-5有可能免费提供,而同时也会发布开源的技术。
《创新者的窘境》一书中曾提到,“为什么成功的大企业会倒掉?因为他们按照既定技术轨道发展自己,能力结构逐渐固化,成为无法变革成功的死穴”。
外部市场环境瞬息万变,企业的战略规划与组织架构必须与时俱进、实现自主进化,否则必将被市场无情淘汰。大模型行业同样遵循这一规律。“AI 六小虎”的发展进程仍在持续,百川和智谱手握大量资金积极“冬储”,为未来布局。鉴于此,大模型行业未来的格局充满变数,当下实难作出精准预测。
但唯一可以确定的是,DeepSeek已经成为了美国企业的“眼中钉肉中刺”。
3月13日,OpenAI向白宫提交了一份15页的信函,称要求美国政府禁用DeepSeek,并向特朗普政府建议实施“AI技术出口管制”,限制AI技术流向中国等国家。
正如OpenAI全球事务副主管勒汉在信中称:“虽然美国目前在AI领域仍保持领先,但DeepSeek的出现显示我们的领先优势正在缩小。”
这场大模型之战仍将持续,短时间内难见分晓。各方在技术研发、市场拓展、应用创新等维度的较量正酣,未来的竞争态势愈发复杂,鹿死谁手尚未可知。
(本文首发于钛媒体App,作者|林志佳)
 微信扫一扫打赏
微信扫一扫打赏
 支付宝扫一扫打赏
支付宝扫一扫打赏





